邓东灵研究组应用强化机器学习算法实现量子编译优化
2020年10月23日 浏览次数: 0
近日,清华大学交叉信息研究院邓东灵研究组与北京大学张亿研究组合作,首次把强化机器学习的方法引入到量子编译中,实现了优化量子编译线路的普适算法。该成果论文Topological Quantum Compiling with Reinforcement Learning (《拓扑量子编译与强化学习》)近日发表于国际学术期刊Physical Review Letters(《物理评论快报》)。
量子编译是指把量子算法分解为一系列可以在量子硬件上实现的基本门操作的过程,它是实现量子计算的基石。传统方法在解决这一问题时面临一些困难:如索罗维-基塔耶夫算法(Solovay-Kitaev算法)不能输出长度最优的量子编译序列以实现某个特定的量子门操作,而暴力穷举算法虽可实现长度最优,但其耗时随序列长度指数增加。
最近,在机器学习领域有一个重要进展是通过强化学习算法可以有效解决魔方还原问题。邓东灵课题组与合作者通过研究发现,魔方还原问题与量子编译问题有很强的相似性(如下表1所示),因此可以用强化学习的方法来解决量子编译问题。该论文提出了一个解决量子编译问题的普适强化学习算法(如下图1所示)。此算法不需要辅助量子比特,也不依赖于实现通用量子计算的基本量子门操作的集合。为展示此算法相对传统算法的优势,该论文研究了拓扑量子计算中对斐波那契任意子(Fibonacci任意子)的编译问题。

表1: 量子编译问题与魔方还原问题的相似性。
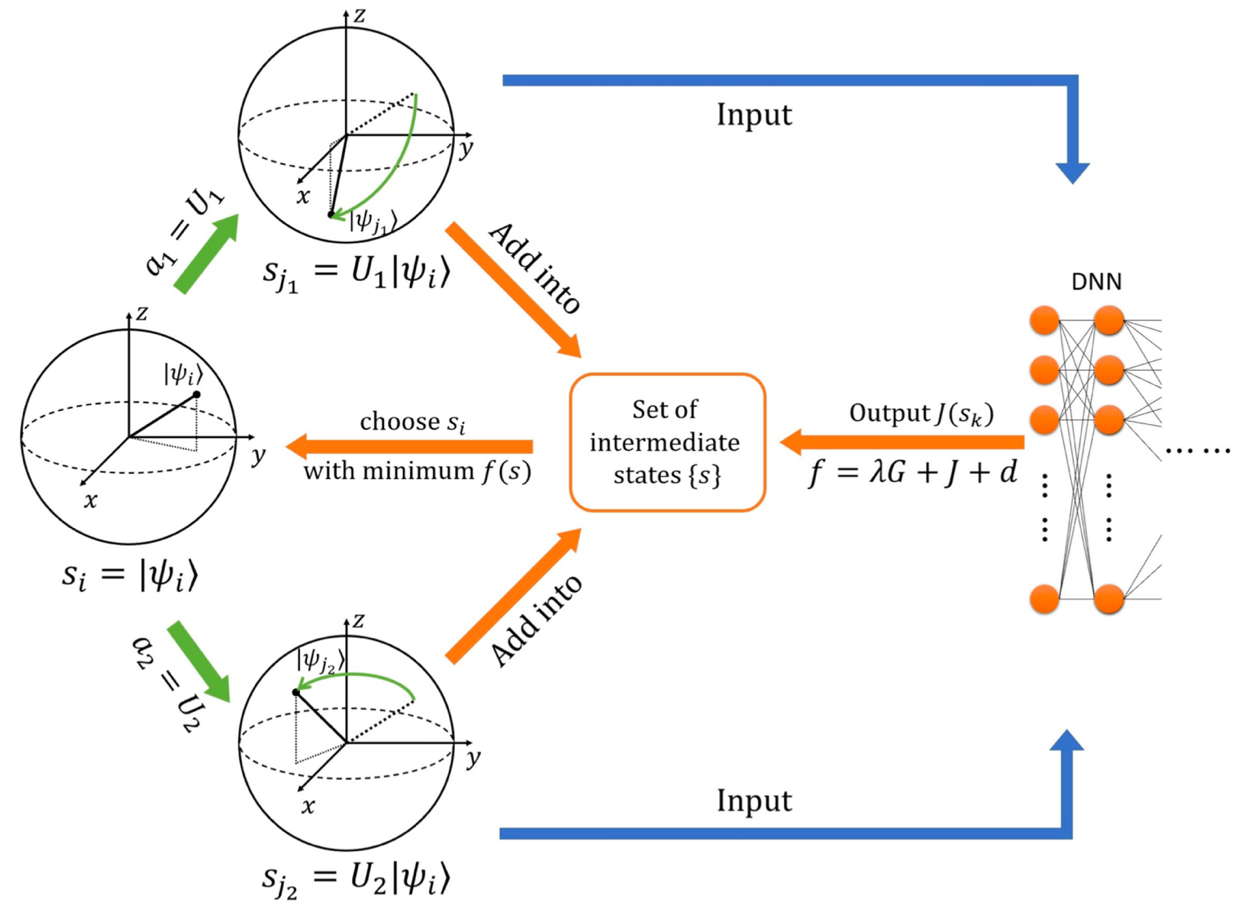
Figure 1: 量子编译的强化机器学习算法。
研究结果表明,对于给定精度,通过强化学习的算法可以得到接近长度最优的量子编译序列,且所需时间与给定精度倒数的对数成线性关系。因此,此算法所得量子编译序列长度远优于Solovay-Kitaev算法,而所需时间相比暴力穷举算法有指数优势。此研究成果在强化机器学习与量子计算之间建立了新的桥梁,提出了较优的量子编译算法,将对未来量子计算的理论与实验研究产生影响。
论文共同通讯作者为邓东灵助理教授与张亿助理教授。交叉信息院访问学生张远航(现为加利福尼亚大学圣迭戈分校博士生)为论文第一作者,北京大学博士生郑沛林为第二作者。此项研究工作得到了清华大学启动经费、北京大学启动经费以及上海期智研究院的支持。
论文链接:https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.125.170501